LLM Workflow Architecture
02/07/2026
GraphRAG version 1.2.0
Two specialized workflows handle all LLM interactions:
LLM Call: Encapsulates the logic of calling an LLM model. The Chat Model node is provider-specific; changing providers means changing only this node. It supports a primary/fallback model pattern and structured output validation.
Utils - Calculate LLM usage: Fetches execution details via the n8n API, parses them for AI agent requests, and extracts and summarizes token usage. This is called at the end of post-processing to generate the
TOKEN_USAGE_DETAILSSSE message.
The LLM Call workflow is used to encapsulate the logic of calling an LLM model.
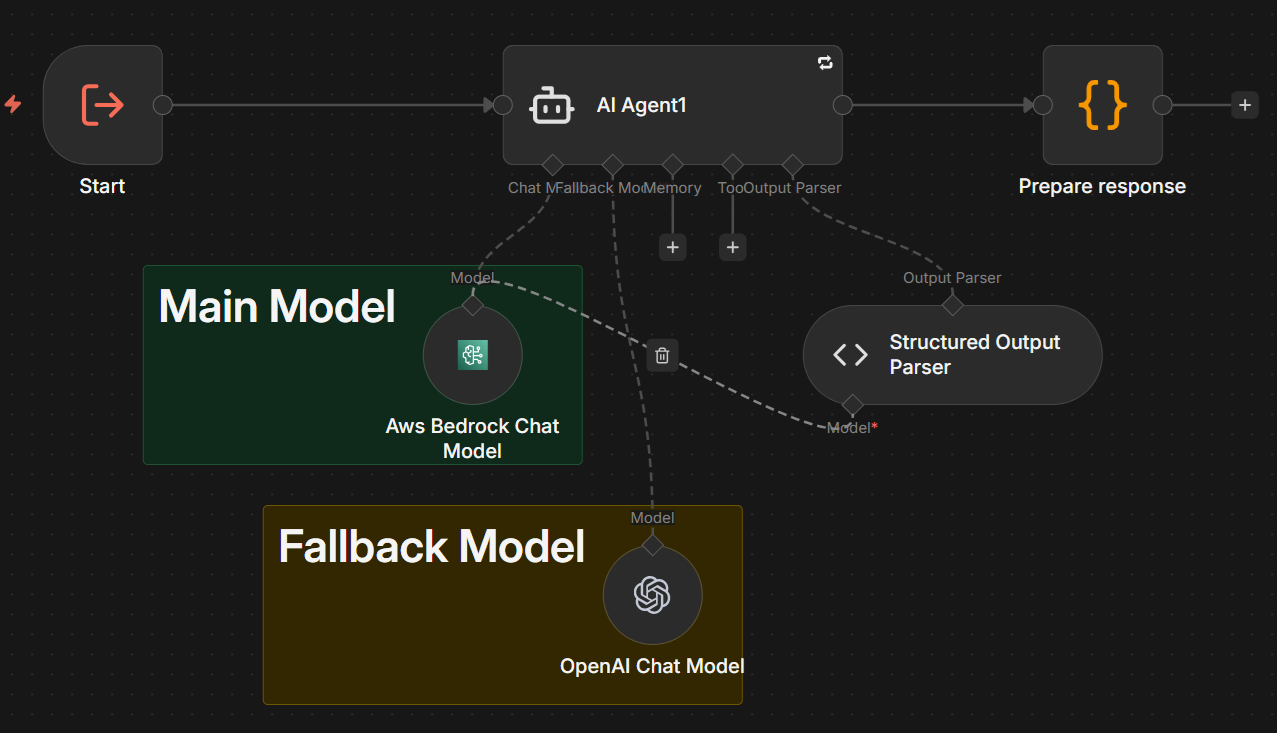 |
Since the XYZ Chat Model is provider-specific, changing the provider can only be manually done here by modifying the main and fallback model modes.
The Utils - Calculate LLM usage workflow is a utility used with LLM Call to calculate token usage.
To achieve this, an n8n API call for execution details is used; the response is parsed to extract and summarize only the token usage information.
The token usage for each step using an LLM as well as the total sum of tokens used for that question are calculated at the end of the post-processing phase of GraphRAG’s question answering process.
In order to do this, all details of the ongoing workflow execution are fetched via the n8n API, traced for requests to AI agents, and parsed to extract and summarize only the token usage information. This behavior can be found in the workflow Utils - Calculate LLM usage as shown below.

Above, we can see how, after the data is retrieved with the n8n API call and its parameters and execution ID are validated, the workflow retrieves the API key and uses it to find out about the token usage. The Main workflow then generates and sends a TOKEN_USAGE_DETAILS SSE message.